Kubernetes最佳实践(1)- 设置基本服务
从今天开始翻译《Kubernetes Best Practice》一书,边学习边总结,翻译不到位的地方欢迎指正。
第 1 章 设置基本服务
本章介绍在 Kubernetes 中设置简单多层应用程序的实践。该应用程序由一个简单的 Web 应用程序和一个数据库组成。虽然这可能不是最复杂的应用程序,但它是开始定向管理 Kubernetes 中应用程序的好地方。
应用程序概述
我们将用于示例的应用程序并不特别复杂。它是一种简单的日志服务,将其数据存储在 Redis 后端中。它有一个单独的静态文件服务器使用 NGINX。它在单个 URL 上显示两个 Web 路径。这些路径适用于日志的 RESTful 应用程序编程接口 (API)、https://my-host.io/api 和主 URL 上的文件服务器 https://my-host.io 它使用 Let’s Encrypt service 来管理安全套接字层 (SSL) 证书。图 1-1显示了应用程序的关系图。在本章中,我们构建了此应用程序,首先使用 YAML 配置文件,然后使用 Helm 图表。
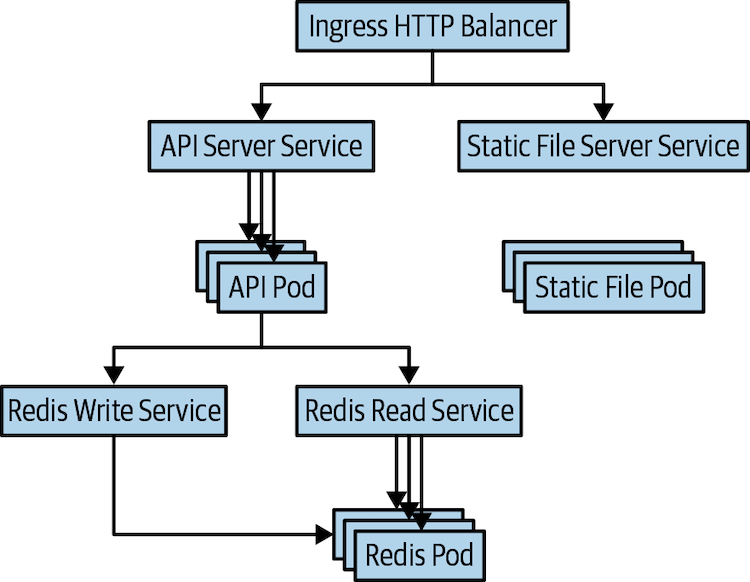
图 1-1 应用程序图
管理配置文件
在详细讨论如何在 Kubernetes 中构建此应用程序之前,有必要讨论一下我们如何管理配置本身。在 Kubernetes 中,一切都是声明性地表示。这意味着您在群集中记下应用程序的预期状态(通常在 YAML 或 JSON 文件中),这些声明的所需状态定义应用程序的所有部分。这种声明性方法比命令式方法更可取,在这种命令式方法中,群集的状态是群集的一系列更改的总和。如果群集是按命令配置的,则很难理解和复制是如何处于群集中该状态的。这使得理解应用程序或从应用程序问题中恢复变得非常困难。
声明应用程序状态时,人们通常更喜欢 YAML 而不是 JSON,尽管 Kubernetes 支持这两种应用程序。这是因为 YAML 比 JSON 更冗长,更可编辑。但是,值得注意的是,YAML 对缩进敏感;Kubernetes 配置中的错误通常可追溯到 YAML 中的缩进不正确。如果事情没有按预期进行,通常检查缩进是否错误。
由于这些 YAML 文件中包含的声明性状态是应用程序的真相来源,因此正确管理此状态对于应用程序的成功至关重要。修改应用程序的所需状态时,您需要能够管理更改、验证更改是否正确、审核谁进行了更改,并在更改失败时可能回滚。幸运的是,在软件工程方面,我们已经开发了必要的工具来管理声明状态的更改以及审核和回滚。也就是说,有关版本控制和代码评审的最佳做法直接应用于管理应用程序的声明性状态的任务。
如今,大多数人将他们的 Kubernetes 配置存储在 Git 中。尽管版本控制系统的具体细节并不重要,但 Kubernetes 生态系统中的许多工具都希望获得 Git 仓库中的文件。对于代码评审,存在更多的异质性,尽管 GitHub 显然相当流行,但其他人使用本地代码评审工具或服务。不管您如何实现应用程序配置的代码审查,您都应该像对待源代码控制一样对待它。
在为应用程序布置文件系统时,通常值得使用文件系统附带的文件夹组织来组织组件。通常,单个目录用于包含应用程序服务,无论应用程序服务的定义对您的团队都很有用。该目录中,子目录用于应用程序的子组件。
对于我们的应用程序,我们按照如下方式布置文件:
1journal/
2 frontend/
3 redis/
4 fileserver/
每个目录中都有定义服务所需的具体 YAML 文件。稍后您将看到,当我们开始将应用程序部署到多个不同的区域或群集时,此文件布局将变得更加复杂。
使用 Deployments 创建副本服务
为了描述我们的应用程序,我们将从前端开始向下工作。日志的前端应用程序是在 TypeScript 中实现的 Node.js 应用程序。完整的应用程序有点太大,无法包含在书中。应用程序在端口 8080 上公开 HTTP 服务,该服务为*/api/**路径提供请求,并使用 Redis 后端添加、删除或返回当前日志分录。此应用程序可以使用包含的 Dockerfile 构建到容器映像中,并推送到您自己的镜像仓库。然后,在以下 YAML 示例中替换此镜像名称。
Dockerfile
1FROM node:10-alpine
2
3COPY server.js /server.js
4
5RUN npm install -g redis
6
7CMD node /server.js
server.js
1const http = require('http');
2const redis = require('redis');
3
4const client = redis.createClient({
5 'host': '127.0.0.1'
6});
7
8const port = 8080;
9
10const requestHandler = (request, response) => {
11 console.log(request.url);
12 if (!request.url.startsWith('/api')) {
13 response.writeHead(404);
14 response.end('Not found');
15 return;
16 }
17 if (request.method != 'GET' && request.method != 'POST') {
18 response.writeHead(400);
19 response.end('Unsupported method.');
20 return;
21 }
22 const key = 'journal-key';
23 client.get(key, (err, value) => {
24 if (err) {
25 response.writeHead(500);
26 response.end(err.toString());
27 return;
28 }
29 var journals = [];
30 if (value) {
31 journals = JSON.parse(value);
32 }
33 if (request.method == 'GET') {
34 response.writeHead(200);
35 response.end(JSON.stringify(journals));
36 }
37 if (request.method == 'POST') {
38 try {
39 let body = [];
40 request.on('data', (chunk) => {
41 body.push(chunk);
42 }).on('end', () => {
43 body = Buffer.concat(body).toString();
44 const msg = JSON.parse(body);
45 journals.push(msg);
46 client.set(key, JSON.stringify(journals));
47 response.writeHead(200);
48 response.end(JSON.stringify(journals));
49 });
50 } catch (err) {
51 response.writeHeader(500);
52 response.end(err.toString());
53 return;
54 }
55 }
56 });
57 return;
58}
59
60const server = http.createServer(requestHandler);
61
62server.listen(port, (err) => {
63 if (err) {
64 return console.log('could not start server', err);
65 }
66
67 console.log('api server up and running.');
68})
镜像管理的最佳实践
一般来说,构建和维护容器镜像超出了本书的范围,但有必要确定一些用于构建和命名镜像的一般最佳实践。通常,镜像生成过程容易受到"供应链攻击"。在此类攻击中,恶意用户从随后内置到应用程序中的受信任源将代码或二进制文件注入到某个依赖项中。由于此类攻击的风险,因此在构建镜像时,仅将其基于已知且受信任的镜像提供程序至关重要。或者,您可以从头开始生成所有映像。对于可以构建静态二进制文件的某些语言(例如 Go),从头开始构建很容易,但对于 Python、JavaScript 或 Ruby 等解释语言来说,构建起来要复杂得多。
镜像的其他最佳实践与命名有关。尽管镜像仓库中的容器镜像版本在理论上是可变的,但您应该将版本标记视为不可变。特别是,语义版本和生成映像的提交的 SHA 哈希的某种组合是命名映像(例如*,v1.0.1-bfeda01f*) 的一种好做法。如果未指定镜像版本,则默认情况下使用latest。虽然这在开发中很方便,但对于生产使用来说,这是一个不好的做法,因为每次生成新镜像时latest都会明显发生突变。
创建带副本的应用程序
我们的前端应用程序是无状态的;它完全依赖于 Redis 后端的状态。因此,我们可以任意复制它,而不会影响流量。尽管我们的应用程序不太可能维持大规模使用,但最好至少使用两个副本运行,以便处理意外崩溃或推出应用程序的新版本而不停机。
尽管在 Kubernetes 中,ReplicaSet 是管理副本容器化应用程序的资源,但不是直接使用它的最佳做法。而是使用 Deployment 资源。Deployment 将 ReplicaSet 的复制功能与版本控制以及执行分阶段部署的功能相结合。通过使用 Deployment,您可以使用 Kubernetes 的内置工具从应用程序的一个版本移动到下一个版本。
我们应用程序的 Kubernetes Deployment 资源如下所示:
1apiVersion: extensions/v1beta1
2kind: Deployment
3metadata:
4 labels:
5 app: frontend
6 name: frontend
7 namespace: default
8spec:
9 replicas: 2
10 selector:
11 matchLabels:
12 app: frontend
13 template:
14 metadata:
15 labels:
16 app: frontend
17 spec:
18 containers:
19 - image: my-repo/journal-server:v1-abcde
20 imagePullPolicy: IfNotPresent
21 name: frontend
22 resources:
23 request:
24 cpu: "1.0"
25 memory: "1G"
26 limits:
27 cpu: "1.0"
28 memory: "1G"
在 Deployment 中需要注意几件事。首先,我们使用 label 来标识 Deployment 以及 Deployment 创建的 ReplicaSets 和 pods。我们已向所有这些资源添加了 label,layer: frontend。以便我们可以在单个请求中检查特定层的所有资源。您将看到,当我们添加其他资源时,我们将遵循相同的实践。
此外,我们在 YAML 中的多个位置添加了注释。尽管这些注释不会进入存储在服务器上的 Kubernetes 资源,就像代码中的注释一样,但它们有助于指导首次查看此配置的人员。
您还应注意,对于 Deployment 中的容器,我们同时指定了 request 和 limits 资源请求,并且将 request 设置为等于 limits。运行应用程序时,request 是在其运行的主机上保证的保留。limits 是容器将允许的最大资源使用量。一开始,将 request 设置为"limits"将导致应用程序最可预测的行为。这种可预测性是以资源利用率为代价的。由于将"request"设置为"limit"可防止应用程序过度计划或消耗过多的空闲资源,因此除非您非常非常仔细地调整"request"和"limits",否则您将无法提高最大利用率。随着您对 Kubernetes 资源模型的理解越来越先进,您可以考虑独立修改应用程序的request 和limit ,但一般来说,大多数用户发现,可预测性的稳定性值得降低利用。
现在,我们已经定义了 Deployment 资源,我们将将其签入版本控制,并将其部署到 Kubernetes:
1git add frontend/deployment.yaml
2git commit -m "Added deployment" frontend/deployment.yaml
3kubectl apply -f frontend/deployment.yaml
这也是一种最佳做法,以确保群集的内容与源代码管理的内容完全匹配。确保这一点的最佳模式是采用 GitOps 方法,并且仅使用持续集成 (CI)/持续交付 (CD) 自动化从源代码管理的特定分支部署到生产。通过这种方式,您可以保证源代码管理与生产匹配。尽管对于一个简单的应用程序来说,完整的 CI/CD 流程可能看起来有些过分,但自动化本身,独立于它提供的可靠性,通常值得花时间来设置它。而且,CI/CD 很难改装成现有的、紧急部署的应用程序。
此外,还有一些应用程序描述 YAML(例如,ConfigMap、Secret 和 Volumes)以及 pod 服务质量,我们在后面的部分中对其进行了检查。
为 HTTP 流量设置外部入口
我们应用程序的容器现已部署,但目前任何人都无法访问该应用程序。默认情况下,群集资源仅在群集内可用。为了对外部暴露我们的应用程序,我们需要创建一个服务和负载均衡器来提供外部 IP 地址,并将流量带到我们的容器。对于外部曝露,我们实际上将使用两个 Kubernetes 资源。第一种是负载均衡传输控制协议 (TCP) 或用户数据报协议 (UDP) 流量的服务。在我们的例子中,我们使用的是TCP协议。第二个是 Ingress 资源,它提供 HTTP(S) 负载平衡,并基于 HTTP 路径和主机的智能请求路由。使用这样的简单应用程序,您可能想知道为什么我们选择使用更复杂的 Ingress,但正如在后面的部分中所看到的,即使这个简单的应用程序也会提供来自两个不同服务的 HTTP 请求。此外,在边缘拥有入口,可以灵活地扩展我们的服务。
在定义入口资源之前,需要有一个 Kubernetes Service才能指向Ingress。我们将使用 label 将 Service 定向到我们在上一节中创建的pods。与 Deployment 相比,Service 的定义要简单得多,如下所示:
1apiVersion: v1
2kind: Service
3metadata:
4 labels:
5 app: frontend
6 name: frontend
7 namespace: default
8spec:
9 ports:
10 - port: 8080
11 protocol: TCP
12 targetPort: 8080
13 selector:
14 app: frontend
15 type: ClusterIP
定义好 Service 后,可以定义 Ingress 资源。与 Service 资源不同,Ingress 需要 Ingress Controller 容器在群集中运行。您可以从许多不同的实现中进行选择,这些实现由云提供商提供,或者使用开源服务器实现。如果选择安装开源ingress provider,最好使用Helm 包管理器来安装和维护它。Ingress provider中nginx或haproxy是受欢迎的选择:
1apiVersion: extensions/v1beta1
2kind: Ingress
3metadata:
4 name: frontend-ingress
5spec:
6 rules:
7 - http:
8 paths:
9 - path: /api
10 backend:
11 serviceName: frontend
12 servicePort: 8080
使用 ConfigMap 配置应用程序
每个应用程序都需要一定程度的配置。这可以是每页显示的日志条目数、特定背景的颜色、特殊假日显示或许多其他类型的配置。通常,将此类配置信息与应用程序本身分离是最佳做法。
这种分离有几个不同的原因。首先,您可能需要根据设置使用不同的配置配置相同的应用程序二进制文件。在欧洲,你可能想要点一个复活节特别节目,而在中国,你可能想为中国新年展示一个特别的。除了这种环境专业化之外,分离还有敏捷性的原因。通常,二进制版本包含多个不同的新功能;如果通过代码打开这些功能,修改活动功能的唯一方法是生成和发布新的二进制文件,这可能是一个代价高且缓慢的过程。
使用配置来激活一组功能意味着您可以快速(甚至动态)激活和停用功能,以响应用户需求或应用程序代码故障。功能可以基于每个功能进行回滚。这种灵活性可确保您在大多数功能方面不断取得进展,即使某些功能需要回滚以解决性能或正确性问题。
在 Kubernetes 中,此类配置由名为 ConfigMap 的资源表示。ConfigMap 包含多个表示配置信息或文件的键/值对。此配置信息可以通过文件或环境变量呈现给pods中的容器。假设您要将联机日志应用程序配置为显示每页可配置的日志分录数。为此,您可以定义 ConfigMap,如下所示:
1kubectl create configmap frontend-config --from-literal=journalEntries=10
要配置应用程序,请将配置信息公开为应用程序本身中的环境变量。为此,可以将以下内容添加到前面定义的"Deployment"中的:container资源
1...
2# The containers array in the PodTemplate inside the Deployment
3containers:
4 - name: frontend
5 ...
6 env:
7 - name: JOURNAL_ENTRIES
8 valueFrom:
9 configMapKeyRef:
10 name: frontend-config
11 key: journalEntries
12...
虽然这演示了如何使用 ConfigMap 配置应用程序,但是在部署的实际环境中,您需要通过每周部署甚至更频繁地推出对此配置进行常规更改。简单地更改 ConfigMap 本身来实现这一点可能很诱人,但这不是最佳实践。这样做有几个原因:首先,更改配置实际上不会触发对现有 Pod 的更新。只有当重新启动pod时才会应用配置。因此,部署不是基于健康状态的,可以是临时的,也可以是随机的。
更好的方法是将版本号放在 ConfigMap 本身的名称中。不是叫它frontend-config,而叫它frontend-config-v1。当您希望进行更改时,您需要创建一个新的 ConfigMap v2,然后更新部署资源以使用该配置,而不是直接更新 ConfigMap。当您这样做作时,将使用适当的健康状态检查和更改之间的暂停自动触发Deployment部署。此外,如果需要回滚,v1配置位于集群中,回滚只需再次更新Deployment即可。
使用 Secrets 管理身份验证
到目前为止,我们还没有真正讨论我们的前端连接到的 Redis 服务。但是,在任何实际应用中,我们需要保护服务之间的连接。这在一定程度上是为了确保用户及其数据的安全性,此外,还必须防止错误,如将开发前端与生产数据库连接。
使用简单密码对 Redis 数据库进行身份验证。如果认为此密码存储在应用程序的源代码中或镜像中的文件中,可能很方便,但由于各种原因,这些都是不好的想法。首先,您已经泄露了您的机密(密码)到一个环境,你不一定考虑访问控制。如果将密码放入源代码管理中,则表示要对齐对源的访问以及对所有机密的访问。这可能不正确。您可能拥有一组更广泛的用户,他们可以访问您的源代码,而不是真正有权访问您的 Redis 实例。同样,有权访问容器镜像的用户不一定有权访问您的生产数据库。
除了对访问控制的关注之外,避免将机密绑定到源代码控制和/或镜像的另一个原因是参数化。您希望能够在各种环境中使用相同的源代码和镜像(例如,开发、金丝雀和生产)。如果机密在源代码或镜像中紧密绑定,则需要每个环境使用不同的镜像(或不同的代码)。
在上一节中看到 ConfigMaps 后,您可能会立即认为密码可以存储为配置,然后作为特定于应用程序的配置填充到应用程序中。认为配置与应用程序的分离与将机密与应用程序分离是一回事,这是对的。但事实上,secret本身就是一个重要的概念。您可能希望以不同于配置的方式处理secret的访问控制、处理和更新。更重要的是,您希望开发人员在访问机密时与访问配置时的想法不同。出于这些原因,Kubernetes 具有用于管理机密数据的内置机密资源。
您可以为 Redis 数据库创建密钥密码,如下所示:
1kubectl create secret generic redis-passwd --from-literal=passwd=${RANDOM}
显然,您可能希望使用随机数以外的内容来输入密码。此外,您可能想要使用秘密/密钥管理服务,或者通过云提供商(如 Microsoft Azure 密钥保管库)或开源项目(如 HashiCorp 的保管库)。"。当您使用密钥管理服务时,它们通常与 Kubernetes 机密有更严格的集成。
注意
默认情况下,Kubernetes 中的秘密被未加密存储。如果要存储加密机密,可以与密钥提供程序集成,为您提供 Kubernetes 将用于加密群集中的所有机密的密钥。请注意,虽然这保护了密钥免受对数据库etcd的直接攻击,但您仍然需要确保通过 Kubernetes API 服务器进行的访问得到正确保护。
将 Redis 密码作为机密存储在 Kubernetes 中后,在部署到 Kubernetes 时,需要将该secret绑定到正在运行的应用程序。为此,您可以使用 Kubernetes 卷。卷实际上是一个文件或目录,可以装载到用户指定位置的运行容器中。对于机密,卷被创建为 tmpfs RAM 支持的文件系统,然后装入到容器中。这可确保即使计算机受到物理危害(在云中不太可能,但在数据中心中可能),攻击者也很难获取secrets。
要向 Deployment 中添加 secret 卷,您需要在Deployment 的 YAML 中指定两个新条目。第一个是将卷添加到 Pod 的 Pod 的条目:volume
1...
2 volumes:
3 - name: passwd-volume
4 secret:
5 secretName: redis-passwd
使用容器中的卷时,需要将其安装到特定容器中。通过容器描述中的字段执行此操作:volumeMounts
1...
2 volumeMounts:
3 - name: passwd-volume
4 readOnly: true
5 mountPath: "/etc/redis-passwd"
6...
这将将secret卷装入目录,以便从客户端代码访问。综上分在一起,您可以按照以下方式完成完整的部署:redis-passwd
1apiVersion: extensions/v1beta1
2kind: Deployment
3metadata:
4 labels:
5 app: frontend
6 name: frontend
7 namespace: default
8spec:
9 replicas: 2
10 selector:
11 matchLabels:
12 app: frontend
13 template:
14 metadata:
15 labels:
16 app: frontend
17 spec:
18 containers:
19 - image: my-repo/journal-server:v1-abcde
20 imagePullPolicy: IfNotPresent
21 name: frontend
22 volumeMounts:
23 - name: passwd-volume
24 readOnly: true
25 mountPath: "/etc/redis-passwd"
26 resources:
27 request:
28 cpu: "1.0"
29 memory: "1G"
30 limits:
31 cpu: "1.0"
32 memory: "1G"
33 volumes:
34 - name: passwd-volume
35 secret:
36 secretName: redis-passwd
此时,我们已将客户端应用程序配置为具有可用于对 Redis 服务进行身份验证的secret。配置 Redis 以使用此secret是相似的;我们把它装入Redis pod,并从文件加载密码。
部署一个简单有状态的数据库服务
尽管在概念上部署有状态应用程序类似于部署客户端(如前端),但状态会带来更多的复杂情况。首先,在 Kubernetes 中,可以出于多种原因(如节点运行状况、升级或重新平衡)重新安排pod。发生这种情况时,pod可能会移动到其他计算机。如果与 Redis 实例关联的数据位于任何特定计算机上或容器本身,则当容器迁移或重新启动时,该数据将丢失。为了防止这种情况,在 Kubernet 中运行有状态工作负载时,使用远程持久卷来管理与应用程序关联的状态非常重要。
Kubernetes 中存在许多不同的持久卷实现,但它们都有共同的特征。与前面描述的 secret 卷一样,它们与pod相关联,并安装在特定位置的容器中。与 secret 不同,持久卷通常是通过某种网络协议装载的远程存储,无论是基于文件的,如网络文件系统 (NFS) 或服务器消息块 (SMB), 还是基于数据块(iSCSI、基于云的磁盘等)。通常,对于数据库等应用程序,基于块的磁盘更可取,因为它们通常提供更好的性能,但如果性能不太考虑,则基于文件的磁盘有时可以提供更大的灵活性。
注意
管理状态一般是复杂的,Kubernetes 也不例外。如果在支持有状态服务(例如,MySQL 即服务、Redis 作为服务)的环境中运行,则通常最好使用这些有状态服务。最初,有状态软件即服务 (SaaS) 的成本溢价可能看起来非常昂贵,但当您考虑状态的所有操作要求(备份、数据本地化、冗余等)以及 Kubernetes 群集中的状态使得在群集之间移动应用程序变得困难这一事实时,很明显,在大多数情况下,存储 SaaS 值得溢价。在存储 SaaS 不可用的本地环境中,让专用团队为整个组织提供存储即服务肯定比允许每个团队滚动自己的服务更好。
要部署 Redis 服务,我们使用 StatefulSet 资源。在初始 Kubernetes 发布后添加,作为对副本集资源的补充,StatefulSet 提供了稍强的保证,如一致的名称(无随机哈希!)和定义的放大和缩减顺序。部署单个实例时,这不太重要,但当您要部署复制状态时,这些属性非常方便。
要获取我们的 Redis 持久卷,我们使用 PersistentVolumeClaim。您可以将声明视为"资源请求"。我们的 Redis 抽象地声明它需要 50 GB 的存储空间,而 Kubernetes 群集决定如何预配适当的持久卷。原因有二。第一种情况是,我们可以编写一个在不同云和本地之间可移植的 StatefulSet,其中磁盘的详细信息可能有所不同。另一个原因是,尽管许多持久卷类型只能装载到单个pod,但我们可以使用卷声明来编写可复制的模板,同时为每个容器分配其自己的特定持久性卷。
以下示例显示了具有持久卷的 Redis 状态化设置:
1apiVersion: apps/v1
2kind: StatefulSet
3metadata:
4 name: redis
5spec:
6 serviceName: "redis"
7 replicas: 1
8 selector:
9 matchLabels:
10 app: redis
11 template:
12 metadata:
13 labels:
14 app: redis
15 spec:
16 containers:
17 - name: redis
18 image: redis:5-alpine
19 ports:
20 - containerPort: 6379
21 name: redis
22 volumeMounts:
23 - name: data
24 mountPath: /data
25 volumeClaimTemplates:
26 - metadata:
27 name: data
28 spec:
29 accessModes: [ "ReadWriteOnce" ]
30 resources:
31 requests:
32 storage: 10Gi
这将部署 Redis 服务的单个实例,但假设您要复制 Redis 群集,以便横向扩展读取和恢复故障。为此,您需要将副本的数量明显增加到三个,但还需要确保两个新副本连接到 Redis 的写入主机。
当您为 Redis 状态设置创建无头服务时,它将创建一个 DNS 条目redis-0.redis ;这是第一个副本的 IP 地址。您可以使用它创建一个简单的脚本,可以在所有包含器中启动:
1#!/bin/bash
2
3PASSWORD=$(cat /etc/redis-passwd/passwd)
4
5if [[ "${HOSTNAME}" == "redis-0" ]]; then
6 redis-server --requirepass ${PASSWORD}
7else
8 redis-server --slaveof redis-0.redis 6379 --masterauth ${PASSWORD} --requirepass ${PASSWORD}
9fi
可以创建此脚本作为 ConfigMap:
1kubectl create configmap redis-config --from-file=launch.sh=launch.sh
然后,将这个 ConfigMap 添加到 StatefulSet 中,并将其用作容器的命令。让我们还添加我们在本章前面创建的身份验证密码。
完整的三个副本 Redis 如下所示:
1apiVersion: apps/v1
2kind: StatefulSet
3metadata:
4 name: redis
5spec:
6 serviceName: "redis"
7 replicas: 3
8 selector:
9 matchLabels:
10 app: redis
11 template:
12 metadata:
13 labels:
14 app: redis
15 spec:
16 containers:
17 - name: redis
18 image: redis:5-alpine
19 ports:
20 - containerPort: 6379
21 name: redis
22 volumeMounts:
23 - name: data
24 mountPath: /data
25 - name: script
26 mountPath: /script/launch.sh
27 subPath: launch.sh
28 - name: passwd-volume
29 mountPath: /etc/redis-passwd
30 command:
31 - sh
32 - -c
33 - /script/launch.sh
34 volumes:
35 - name: script
36 configMap:
37 name: redis-config
38 defaultMode: 0777
39 - name: passwd-volume
40 secret:
41 secretName: redis-passwd
42 volumeClaimTemplates:
43 - metadata:
44 name: data
45 spec:
46 accessModes: [ "ReadWriteOnce" ]
47 resources:
48 requests:
49 storage: 10Gi
使用 Services 创建 TCP 负载平衡器
现在,我们已经部署了有状态的 Redis 服务,我们需要将其提供给前端。为此,我们创建了两个不同的 Kubernetes 服务。第一个是读取 Redis 数据的服务。由于 Redis 正在将数据复制到 StatefulSet 的所有三个成员,因此我们不关心读取我们的请求的哪个成员。因此,我们使用基本服务进行读取:
1apiVersion: v1
2kind: Service
3metadata:
4 labels:
5 app: redis
6 name: redis
7 namespace: default
8spec:
9 ports:
10 - port: 6379
11 protocol: TCP
12 targetPort: 6379
13 selector:
14 app: redis
15 sessionAffinity: None
16 type: ClusterIP
要启用写入,您需要将 Redis 母版(副本#0)作为目标。为此,请创建无头服务。无头服务没有群集 IP 地址;相反,它为状态集中的每个 pod 程序 DNS 条目。这意味着我们可以通过 DNS 名称redis-0.redis访问主机:
1apiVersion: v1
2kind: Service
3metadata:
4 labels:
5 app: redis-write
6 name: redis-write
7spec:
8 clusterIP: None
9 ports:
10 - port: 6379
11 selector:
12 app: redis
因此,当我们想要连接到 Redis 进行写入或事务读取/写入对时,我们可以构建连接到服务器的单独写入客户端。redis-0.redis
使用 Ingress 将流量路由到静态文件服务器
我们应用程序中的最后一个组件是静态文件服务器。静态文件服务器负责提供 HTML、CSS、JavaScript 和图像文件。将静态文件服务与前面描述的 API 服务分开既高效又更集中。我们可以轻松地使用像 NGINX 这样的高性能静态现成文件服务器来提供文件,同时允许我们的开发团队专注于实现 API 所需的代码。
幸运的是,Ingress 资源使这种小型微服务体系结构的来源变得非常简单。与前端一样,我们可以使用 Deployment 资源来描述复制的 NGINX 服务器。让我们将静态镜像构建到 NGINX 容器中,并将其部署到每个副本。Deployment 资源如下所示:
1apiVersion: extensions/v1beta1
2kind: Deployment
3metadata:
4 labels:
5 app: fileserver
6 name: fileserver
7 namespace: default
8spec:
9 replicas: 2
10 selector:
11 matchLabels:
12 app: fileserver
13 template:
14 metadata:
15 labels:
16 app: fileserver
17 spec:
18 containers:
19 - image: my-repo/static-files:v1-abcde
20 imagePullPolicy: Always
21 name: fileserver
22 terminationMessagePath: /dev/termination-log
23 terminationMessagePolicy: File
24 resources:
25 request:
26 cpu: "1.0"
27 memory: "1G"
28 limits:
29 cpu: "1.0"
30 memory: "1G"
31 dnsPolicy: ClusterFirst
32 restartPolicy: Always
现在,静态 Web 服务的副本已启动并运行,同样,您将创建一个Service 资源来充当负载均衡器:
1apiVersion: v1
2kind: Service
3metadata:
4 labels:
5 app: frontend
6 name: frontend
7 namespace: default
8spec:
9 ports:
10 - port: 80
11 protocol: TCP
12 targetPort: 80
13 selector:
14 app: frontend
15 sessionAffinity: None
16 type: ClusterIP
现在,您已经为静态文件服务器提供了服务,请扩展 Ingress 资源以包含新路径。请务必注意,必须将路径/放在路径/api之后,否则它将将 API 请求/api归入静态文件服务器并定向到静态文件服务器。新的入口如下所示:
1apiVersion: extensions/v1beta1
2kind: Ingress
3metadata:
4 name: frontend-ingress
5spec:
6 rules:
7 - http:
8 paths:
9 - path: /api
10 backend:
11 serviceName: frontend
12 servicePort: 8080
13 # NOTE: this should come after /api or else it will hijack requests
14 - path: /
15 backend:
16 serviceName: nginx
17 servicePort: 80
使用 Helm 参数化你的应用程序
到目前为止,我们讨论的所有内容都侧重于将服务的单个实例部署到单个群集。但是,实际上,几乎每个服务和每个服务团队都需要部署到多个不同的环境(即使它们共享一个群集)。即使您是处理单个应用程序的单个开发人员,您可能希望至少具有应用程序的开发版本和生产版本,以便可以在不中断生产用户的情况下迭代和开发。在考虑集成测试和 CI/CD 后,即使使用单个服务和少数开发人员,您也可能希望部署到至少三个不同的环境,如果考虑处理数据中心级故障,可能还会更多。
对于许多团队来说,初始故障模式是简单地将文件从一个群集复制到另一个群集。而不是有一个frontend/目录,还需要有一个frontend-production/ 和 *frontend-development/*目录。之所以如此危险,是因为您现在负责确保这些文件彼此保持同步。如果它们旨在完全相同,这可能很容易,但开发和生产之间会出现一些偏差,因为您将开发新功能;因此,在开发和生产之间,需要开发一些功能。关键是,偏斜既是有意的,也是容易管理的。
实现此目的的另一种选择是使用分支和版本控制,生产和开发分支从中央存储库中引导,并且分支之间的差异清晰可见。对于某些团队来说,这可能是一个可行的选择,但是当您希望将软件同时部署到不同的环境(例如,部署到多个不同云区域的 CI/CD 系统)时,在分支之间移动的机制具有挑战性。
因此,大多数人最终使用模板系统。模板系统将模板(构成应用程序配置的集中主干)与将模板专门化为特定环境配置的参数相结合。通过这种方式,您可以拥有一个通常共享的配置,并根据需要进行有意(和易于理解的)自定义。Kubernetes有各种各样的模板系统,但迄今为止最流行的是一个叫做Helm的系统。
在 Helm 中,应用程序被打包在一个称为chart的文件集合中(在容器和 Kubernetes 的世界里,航海笑话比比皆是)。
chart以Chart.yaml文件开头,该文件定义图表本身的元数据:
1apiVersion: v1
2appVersion: "1.0"
3description: A Helm chart for our frontend journal server.
4name: frontend
5version: 0.1.0
此文件放置在chart目录的根目录中(例如,frontend/)。在此目录中,有一个templates目录,这是放置模板的位置。模板基本上是前例中的 YAML 文件,文件中的某些值替换为参数引用。例如,假设您要对前端中的副本数进行参数化。以前,以下是Deployment 具有的内容:
1...
2spec:
3 replicas: 2
4...
在模板文件中(frontend-deployment.tmpl),它如下所示:
1...
2spec:
3 replicas: {{ .replicaCount }}
4...
这意味着在部署chart时,您将用适当的参数替换副本的值。参数本身在value.yaml文件中定义。每个环境中将有一个应部署应用程序的值文件。此简单chart的值文件如下所示:
1replicaCount: 2
综上合在一起,您可以使用该工具helm部署此chart,如下所示:
1helm install path/to/chart --values path/to/environment/values.yaml
这将参数化您的应用程序并将其部署到 Kubernetes。随着时间的推移,这些参数化将增长到包含应用程序的各种不同环境。
部署服务最佳实践
Kubernetes 是一个强大的系统,可以显得复杂。但是,如果使用以下最佳实践,则设置成功的基本应用程序可能非常简单:
- 大多数服务应部署为 Deployment 资源。Deployment 创建多个的副本,以便冗余和扩展。
- Deployment 可以使用 Service 公开,Service 实际上是负载均衡器。Service 可以在群集(默认值)内或外部公开。如果要公开 HTTP 应用程序,可以使用 Ingress controller 添加请求路由和 SSL 等内容。
- 最终,您需要对应用程序进行参数化,使其配置在不同的环境中具有更好的可重用性。像 Helm这样的打包工具是参数化的最佳选择。
总结
本章中构建的应用程序很简单,但它包含构建更大、更复杂的应用程序所需的几乎所有概念。了解这些部件如何组合在一起以及如何使用基础库 Kubernetes 组件是成功与 Kubernetes 合作的关键。
通过版本控制、代码评审和持续交付服务奠定正确的基础,确保无论您构建什么,它都是以扎实的方式构建的。在后续章节中介绍更高级的主题时,请记住此基本信息。
- 原文作者:黄忠德
- 原文链接:https://huangzhongde.cn/post/2020-02-24-kubernetes_best_practices_ch1_setting_up_a_basic_service/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。