Go爬虫开发
引入
在具体讲解爬虫知识之前,我们首先简单回顾下前面HTTP编程。一种是我们自己编写一个服务器,让浏览器请求我们的服务器。接受请求后分析协议,回发相应数据给浏览器。 另一种,我们可以编写程序充当客户端或者说是用程序模拟浏览器行为,向互联网上现有的服务器发送请求,获取服务器上的数据。例如请求百度,网易,腾讯 等。 实现手段,主要使用的还是net/http这个包。它不仅可以接收浏览器发送过来的请求,实现服务器的功能,也可以模拟浏览器向其它的服务器发送请求。基本的流程如下:
- 构建、发送请求链接
- 获取服务器返回的响应数据
- 过滤、保存、使用得到的数据
- 关闭请求链接。
打印出完整的网页内容,和浏览器获取的内容是一样的。只不过我们写的 .go程序是直接将服务器返回的所有数据内容打印出来,而浏览器是将服务器返回的内容(代码)按照既定的方式加以执行并显示给用户看,所以我们在浏览器上会看到文字,图片等信息。
爬虫简介
其实我们编写的这个模拟浏览器行为的客户端程序,就是一个爬虫。可以获取网络服务器数据到本地。只不过,我们简单粗暴的直接将服务器回发的所有数据获取下来,并没有做任何筛选和处理。 爬虫的定义:网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则自动地抓取万维网信息的程序。 简单来说,就是编写程序,模拟浏览器发送请求,获取到和浏览器一模一样的数据。因此,我们能获取的是浏览器能够接收到的数据。
爬虫获取的数据的用途:
- 呈现数据,呈现在app或者网站上
- 进行数据分析,获得结论
爬虫的分类:
- 通用爬虫:搜索引擎的爬虫
- 聚焦爬虫:针对特定网站的爬虫
聚焦爬虫的工作流程:
- 明确URL (请求的地址,明确爬什么)
- 发送请求,获取响应数据
- 保存响应数据,提取有用信息
- 处理数据(存储、使用)
爬虫爬取哪些数据:
- 资讯公司:特定领域的新闻数据的爬虫
- 金融公司:关于各个公司的动态的信息,
- 酒店/旅游:携程,去哪儿的酒店价格信息/机票,景点价格,其他旅游公司价格信息
- 房地产、高铁:10大房地产楼盘门户网站,政府动态等
- 强生保健医药:医疗数据,价格,目前的市场的行情 对爬虫整体做了简单了解后,我们实现一个爬虫案例,尝试爬取百度贴吧中一些讯息。
爬取百度贴吧
在爬取之前,再回顾一下爬虫的步骤:
-
请求的URL地址,也就是明确目标 (要知道你准备在哪个范围或者网站去搜索),这里我们以“吃鸡”游戏这个贴吧为例,分析地址规律如下:
https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=0 //第一页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=50 //第二页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=100 //第三页
总结规律:“下一页”地址是“前一页”地址 + 50
-
发送请求,获取响应 (将所有的网站的内容全部爬下来)
-
提取数据,去掉对我们没用处的数据
-
处理数据(按照我们想要的方式存储和使用)
示例代码:
1package main
2
3import (
4 "fmt"
5 "net/http"
6 "os"
7 "strconv"
8)
9
10// 实现 读取一个网页内容函数
11func httpGet(url string) (result string, err error) {
12 // 借助 http包的 Get()函数 获取网页数据
13 resp, err := http.Get(url)
14 if err != nil {
15 // 将错误传出
16 return
17 }
18 // 读取结束,关闭resp.Body
19 defer resp.Body.Close()
20
21 buf := make([]byte, 4096)
22 for {
23 // 读取Body内容
24 n, err := resp.Body.Read(buf)
25 if n == 0 {
26 fmt.Println("读完!err:", err)
27 break
28 }
29 // 拼接每次buf中读到的数据,到result中,返回
30 result += string(buf[:n])
31 }
32 return
33}
34
35func working(start, end int) {
36 // 测试
37 fmt.Printf("正在爬取 %d 到 %d 页\n", start, end)
38 // 明确目标:url
39 for i := start; i <= end; i++ {
40 url := "https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=" +
41 strconv.Itoa((i-1)*50)
42 fmt.Printf("正在爬:%d页,%s\n", i, url)
43
44 // 封装函数,读取一页内容,存至 result
45 result, err := httpGet(url)
46 if err != nil {
47 fmt.Println("httpGet err:", err)
48 continue
49 }
50
51 // 将读到的一个网页内容,写出成一个文件。用i.html命名文件
52 fileName := strconv.Itoa(i) + ".html"
53 // 每个网页保存成一个文件
54 f, err := os.Create(fileName)
55 if err != nil {
56 fmt.Println("Create err:", err)
57 continue
58 }
59 f.WriteString(result)
60 // 写完一个文件,关闭一个文件。
61 f.Close()
62 }
63}
64
65func main() {
66 // 指定爬取的起始、终止页面
67 var start, end int
68 fmt.Printf("请输入爬取的起始页( >= 1 ):")
69 fmt.Scan(&start)
70 fmt.Printf("请输入爬取的终止页( >= 起始页):")
71 fmt.Scan(&end)
72
73 // 封装函数,专门完成爬取工作。
74 working(start, end)
75}
运行效果
1请输入爬取的起始页( >= 1 ):1
2请输入爬取的终止页( >= 起始页):5
3正在爬取 1 到 5 页
4正在爬:1页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=0
5读完!err: EOF
6正在爬:2页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=50
7读完!err: EOF
8正在爬:3页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=100
9读完!err: EOF
10正在爬:4页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=150
11读完!err: EOF
12正在爬:5页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=200
13读完!err: EOF
查看保存的文件
1ls *.html
21.html 2.html 3.html 4.html 5.html
并发版网络爬虫
上面实现的案例中,只有一个主协程在爬取网页内容。爬完第一页,再去爬取第二页,再去爬取第三页……这样效率显然很低。学习并发时,我们了解到go语言的goroutine十分轻量级,且能很好的实现并发目的。那么要爬取N页数据,我们可以直接定义N个goroutine分别去爬取,大大提高程序的并发性,执行效率也会高出很多。 将根据URL爬取网页内容、保存生成HTML文件的相关功能封装到函数中。如:
1func spiderPage(idx int) {
2 defer wg.Done()
3 url := "https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=" +
4 strconv.Itoa((idx-1)*50)
5 fmt.Printf("正在爬取:%d页,%s\n", idx, url)
6
7 // 封装函数,读取一页内容,存至 result
8 result, err := httpGet(url)
9 if err != nil {
10 fmt.Println("HttpGet err:", err)
11 return
12 }
13
14 // 将读到的一个网页的内容,写出成一个文件。用i.html命名文件
15 fileName := strconv.Itoa(idx) + ".html"
16 // 每个网页保存成一个文件
17 f, err := os.Create(fileName)
18 if err != nil {
19 fmt.Println("Create err:", err)
20 return
21 }
22 f.WriteString(result)
23 // 写完一个文件,关闭一个文件。
24 f.Close()
25}
working()函数只需循环启动goroutine,调用该函数即可。
1func working(start, end int) {
2 // 明确目标:url
3 for i := start; i <= end; i++ {
4 // 起 go 程并发处理
5 go spiderPage(i)
6 }
7}
但,这样处理有一个问题。主协程很快创建N个goroutine,working()函数调用完毕退出了,而此时子goroutine还没有爬取完网页内容保存成html文件。这里需要主goroutine等待所有子协程调用完成再退出。 可以借助channel 来达到这一目的。 定义一个名为page的通道,将通道引用和循环因子i一起传递到了SpiderPage方法中。
1func working(start, end int) {
2 // 使用 channel 防止主go程提前退出。
3 page := make(chan int)
4 // 明确目标:url
5 for i:=start; i<=end; i++ {
6 // 起 go 程并发处理
7 go spiderPage(i, page)
8 }
9
10 for i:=start; i<=end; i++ {
11 fmt.Printf("爬取%d页面完成!\n", <-page)
12 }
13}
同时在spiderPage函数内爬取网页数据完成后,将i值(代表爬取的第几页)写入page。主协程循环创建N个goroutine之后,要依次读取每一个goroutine借助channel写回的i值。在读取期间,如果page上没有写端写入,主goroutine则会阻塞等待,直到有子协程写入,读取打印第i个页面爬取完毕。
示例代码:
1package main
2
3import (
4 "fmt"
5 "net/http"
6 "os"
7 "strconv"
8)
9
10// 实现 读取一个网页内容函数
11func httpGet(url string) (result string, err error) {
12
13 // 借助 http包的 Get()函数 获取网页数据
14 resp, err := http.Get(url)
15 if err != nil {
16 // 将错误传出
17 return
18 }
19 // 读取结束,关闭resp.Body
20 defer resp.Body.Close()
21
22 buf := make([]byte, 4096)
23 for {
24 // 读取Body内容
25 n, err := resp.Body.Read(buf)
26 if n == 0 {
27 fmt.Println("读完!err:", err)
28 break
29 }
30 // 拼接每次buf中读到的数据,到result中,返回
31 result += string(buf[:n])
32 }
33 return
34}
35
36func spiderPage(idx int, page chan<- int) {
37 url := "https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=" +
38 strconv.Itoa((idx-1)*50)
39 fmt.Printf("正在爬取:%d页,%s\n", idx, url)
40
41 result, err := httpGet(url)
42 // 封装函数,读取一页内容,存至 result
43 if err != nil {
44 fmt.Println("HttpGet err:", err)
45 return
46 }
47
48 // 将读到的一个网页的内容,写出成一个文件。用i.html命名文件
49 fileName := strconv.Itoa(idx) + ".html"
50 f, err := os.Create(fileName)
51 // 每个网页保存成一个文件
52 if err != nil {
53 fmt.Println("Create err:", err)
54 return
55 }
56 f.WriteString(result)
57 // 写完一个文件,关闭一个文件。
58 f.Close()
59
60 // 爬取一个页面完成,写入管道。
61 page <- idx
62}
63
64func working(start, end int) {
65 // 使用 channel 防止主go程提前退出。
66 page := make(chan int)
67 // 明确目标:url
68 for i := start; i <= end; i++ {
69 // 起 go程并发处理
70 go spiderPage(i, page)
71 }
72
73 for i := start; i <= end; i++ {
74 fmt.Printf("爬取%d页面完成!\n", <-page)
75 }
76}
77
78func main() {
79 // 指定爬取的起始、终止页面
80 var start, end int
81 fmt.Printf("请输入爬取的起始页( >= 1 ):")
82 fmt.Scan(&start)
83 fmt.Printf("请输入爬取的终止页( >= 起始页):")
84 fmt.Scan(&end)
85
86 // 封装函数,专门完成爬取工作。
87 working(start, end)
88}
运行效果
1请输入爬取的起始页( >= 1 ):1
2请输入爬取的终止页( >= 起始页):5
3正在爬取:1页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=0
4正在爬取:4页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=150
5正在爬取:5页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=200
6正在爬取:2页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=50
7正在爬取:3页,https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=100
8读完!err: EOF
9爬取2页面完成!
10读完!err: EOF
11爬取1页面完成!
12读完!err: EOF
13爬取4页面完成!
14读完!err: EOF
15爬取3页面完成!
16读完!err: EOF
17爬取5页面完成!
结果是一样的,只是采用并发方式速度要快很多。
正则表达式
简介
在前面的案例中,我们已经完成了将网页的内容进行爬取,并且进行保存。但是,我们并没有对获取的网页数据内容进行筛选,而直接全部保到文件中了。 那如何对爬取到的网页内容进行筛选提取呢?之前学过的string包中的一些字符串操作函数可以完成这类任务,如:搜索(Contains、Index)、替换(Replace)和解析(Split、Join),但是处理网页数据实现起来相对而言复杂度较高。实际在工作中,对于这类字符串拆分提取操作,我们通常使用正则表达式来实现。通过正则表达式提取网页内容要方便许多。 当然如果strings包提供的函数能解决你的问题,那么就尽量使用它来解决。因为他们足够简单、而且性能和可读性都要比正则好。 正则表达式是一种进行模式匹配和文本操纵的复杂而又强大的工具。虽然正则表达式比纯粹的文本匹配效率低,但是它却更灵活。按照它的语法规则,随需构造出的匹配模式就能够从原始文本中筛选出几乎任何你想要得到的字符组合。 对于初学正则表达式的学者,最困难的地方就是它语法中繁多杂乱的符号。所以大多数工作者,都在记忆中保存正则表达式的整体规范,而做不到完全记忆。确保自己手边有一套可靠的正则查找资料,或者能保证随时上网查询即可。对于正则的语法,这里我们捡常用的一些,加以分类介绍:
基本语法
可以借助这个在线网站,测试学习正则表达式基础语法: http://www.itlookit.com/regextest.html
字符类:
| 字符 | 含义 | 举例 |
|---|---|---|
| . | 匹配任意一个字符 | abc.可以匹配abcd、abc9等 |
| [] | 匹配括号中的任意一个字符 | [abc]d可以匹配ad,bd或cd |
| - | 在[]括号内表示字符范围 | [0-9a-zA-Z]可以匹配任意数字和字母 |
| ^ | 位于[]括号内的开头,匹配除括号中的字符之外的任意一个字符 | [^xy]匹配除xy之外的任一字符,因此[^xy]1可以匹配a1,b1但不匹配x1,y1 |
| [[:xxx:]] | grep工具预定义的一些命名字符类 | [[:alpha:]]匹配一个字母,[[:digit:]]匹配一个数字 |
数量限定符:
| 字符 | 含义 | 举例 |
|---|---|---|
| ? | 紧跟在它前面的单元应匹配0次或1次 | [0-9]?.[0-9]匹配0.0,2.3,.5等,由于.在正则表格式中是一个特殊字符,所以需要用\进行转义,取字面值 |
| + | 紧跟在它前面的单元应匹配一次或多次 | [a-zA-Z0-9]+@[a-zA-Z0-9_.-]+匹配email地址 |
| * | 紧跟在它前面的单元应匹配0次或多次 | [0-9][0-9]*匹配至少一位数字,等价于[0-9]+,[a-zA-Z_]+[a-zA-Z_0-9]*匹配C语言的标识符 |
| {N} | 紧跟在它前面的单元应精确匹配N次 | [1-9][0-9]{2}匹配100到999的整数 |
| {N,} | 紧跟在它前面的单元应匹配至少N次 | [1-9][0-9][2,]匹配三位以上(含三位数)的整数 |
| {,M} | 紧跟在它前面的单元应匹配最多M次 | [0-9]{,1}相当于[0-9]? |
| {N,M} | 紧跟在它前面的单元应匹配至少N次,最多M次 | [0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}匹配IP地址 |
其它特殊字符:
| 字符 | 含义 | 举例 |
|---|---|---|
| \ | 转义字符,普通字符转义为特殊字符,特殊字符转义为普通字符 | 普通字符<写成\<表示单词开头的位置,特殊字符.写成\.以及\写成\\就当作普通字符来匹配 |
| () | 将正则表达式的一部分括起来组成一个单元,可以对整个单元使用数量限定副 | ([0-9]{1,3}.){3}[0-9]{1,3}匹配IP地址 |
| | | 连接两个子表达式,表示或的关系 | n(o|either)匹配no或neither |
Go语言通过regexp(regular expression)标准包为正则表达式提供了官方支持,如果你已经使用过其他编程语言提供的正则相关功能,那么你应该对Go语言版本的不会太陌生。但是它们之间也有一些小的差异,因为Go实现的是RE2标准,详细的语法描述可参考:http://code.google.com/p/re2/wiki/Syntax 如遇无法打开,也可参看:http://www.sun190.com/2015/01/re2-%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/
Go语言使用正则
简单来说,Go语言中使用正则表达式只需要两步即可:
-
解析、编译正则表达式。使用
regexp.MustCompile()函数func MustCompile(str string) *Regexp函数的主要作用是将正则表达式中,奇形怪状的符号(如.*?[ …)转换成 Go语言能识别的格式,并将其存成结构体格式,方便编译器识别。 参数:正则表达式字串。建议使用反引号。 返回值:编译后的结构体。解析失败时会产生panic错误。 -
根据解析好的规则(结构体形式),从指定字符串中提取需要的信息。使用
FindAllStringSubmatch()函数func (re *Regexp) FindAllStringSubmatch(s string, n int) [][]string参数1:待解析的字符串。 参数2:匹配的次数。通常传-1,表示匹配所有。 返回值:返回成功匹配的 string。 说明: [ [string1 string2] [string1 string2] [string1 string2] ] 其中:string1: 表示带有匹配参考项的全部字串。string2: 表示去除匹配参考项后的字串。 注意,要使用前面regexp.MustCompile()函数调用的返回值,来调用此函数。 下面是使用正则表达式处理字符串检索的几个小例子。
示例代码1:
1package main
2
3import (
4 "fmt"
5 "regexp"
6)
7
8func main() {
9 str := "abc a7c mfc cat 8ca azc cba"
10 // 1. 解析、编译正则表达式
11 ret := regexp.MustCompile(`a.c`)
12 // 可以不用检查出错情况
13 //ret := regexp.MustCompile(`a[0-9]c`)
14 //ret := regexp.MustCompile(`a\dc`)
15
16 // 2. 提取需要信息
17 alls := ret.FindAllStringSubmatch(str, -1)
18 fmt.Println(alls)
19}
运行结果
1[[abc] [a7c] [azc]]
再看一个提取小数的例子
示例代码2:
1package main
2
3import (
4 "fmt"
5 "regexp"
6)
7
8func main() {
9 str := "3.14 123.123 .68 haha 1.0 abc 7. ab.3 66.6 123."
10
11 // 1. 解析、编译正则表达式
12 //ret := regexp.MustCompile(`\d\.\d`)
13 //ret := regexp.MustCompile(`\d+\.\d`)
14 ret := regexp.MustCompile(`\d+\.\d+`)
15
16 // 2. 提取需要信息
17 result := ret.FindAllStringSubmatch(str, -1)
18
19 fmt.Println(result)
20 fmt.Println("------------------------------------")
21}
运行结果
1[[3.14] [123.123] [1.0] [66.6]]
2------------------------------------
提取网页中<div></div>标签数据的例子
示例代码3:
1package main
2
3import (
4 "fmt"
5 "regexp"
6)
7
8func main() {
9 //反引号
10 str := `
11<!DOCTYPE html>
12<html lang="zh-CN">
13<head>
14 <title>标题</title>
15</head>
16<body>
17 呵呵
18 <div>过年来吃鸡啊</div>
19 <div>hello regexp</div>
20 <div>你在吗?</div>
21</body>
22</html>
23 `
24
25 ret := regexp.MustCompile(`<div>(.*)</div>`)
26 result := ret.FindAllStringSubmatch(str, -1)
27 fmt.Println(result)
28}
运行上述代码,发现可以成功提取<div></div>标签的数据。但输出数据是这样的。
1[[<div>过年来吃鸡啊</div> 过年来吃鸡啊] [<div>hello regexp</div> hello regexp] [<div>你在吗?</div> 你在吗?]]
这里再解释下FindAllStringSubmatch()函数的返回值[ ][ ]string:
[
[string1 string2]
[string1 string2]
[string1 string2]
]
其中:string1: 表示带有匹配参考项的全部字串。string2: 表示去除匹配参考项后的字串。
测试:
1result := ret.FindAllStringSubmatch(str, -1)
2for i := 0; i < len(result); i++ {
3 one := result[i]
4 for i := 0; i < len(one); i++ {
5 fmt.Printf("%d: %s\n", i, one[i])
6 }
7}
8fmt.Println(result)
因此,如果我们想得到不包含<div></div>标签的数据内容,可以使用下标[1]来直接获取。
但是,如果我们将测试代码适当调整。在原str中添加如下标签内容。就不能提取正常数据了。
1<title>标题</title>
2 <div>过年来吃鸡啊</div>
3 <div>hello regexp</div>
4 <div>你在吗?</div>
5 <div>
6 2块钱啥时候还?
7 过了年再说吧!
8 刚买了车,没钱。。。
9 </div>
10<body>呵呵</body>
测试发现,新添加的<div></div>标签中,如果出现换行,则源正则表达式 <div>(.*)</div>不能正确提取数据。因此需要调整正则表达式:<div>(?s:(.*?))</div>。分析这个表达式,有两部分内容。
(?s) 是正则表达式的模式修饰符。即Singleline(单行模式)。表示更改.的含义。使它与每一个字符匹配(包括换行 符\n)。
(.?) 是一个单元分组。“.”匹配任意字符。“?”表重复>=0次匹配。
这个语法,在正则表达式知识里是较难的应用,不必过度学习。我们可以直接记结论:将(?s:(.*?))元组放置于某一特征字串中,可以提取带有这一特征字串的内容。
示例代码4:
1package main
2
3import (
4 "fmt"
5 "regexp"
6)
7
8func main() {
9 // 反引号
10 str := `
11<!DOCTYPE html>
12<html lang="zh-CN">
13<head>
14<title>标题</title>
15</head>
16 <div>过年来吃鸡啊</div>
17 <div>hello regexp</div>
18 <div>你在吗?</div>
19 <div>
20 2块钱啥时候还?
21 过了年再说吧!
22 刚买了车,没钱。。。
23 </div>
24 <body>呵呵</body>
25</html>
26 `
27
28 ret := regexp.MustCompile(`<div>(?s:(.*?))</div>`)
29 result := ret.FindAllStringSubmatch(str, -1)
30 for _, subStr := range result {
31 fmt.Println(subStr[1])
32 }
33}
运行结果
1过年来吃鸡啊
2hello regexp
3你在吗?
4
5 2块钱啥时候还?
6 过了年再说吧!
7 刚买了车,没钱。。。
8
段子爬虫
目标分析
首先打“捧腹网”网站首页,然后单击菜单中“段子”。测试翻页特性是“下一页”+1。
https://www.pengfu.com/xiaohua_1.html 下一页 +1
https://www.pengfu.com/xiaohua_2.html
https://www.pengfu.com/xiaohua_3.html
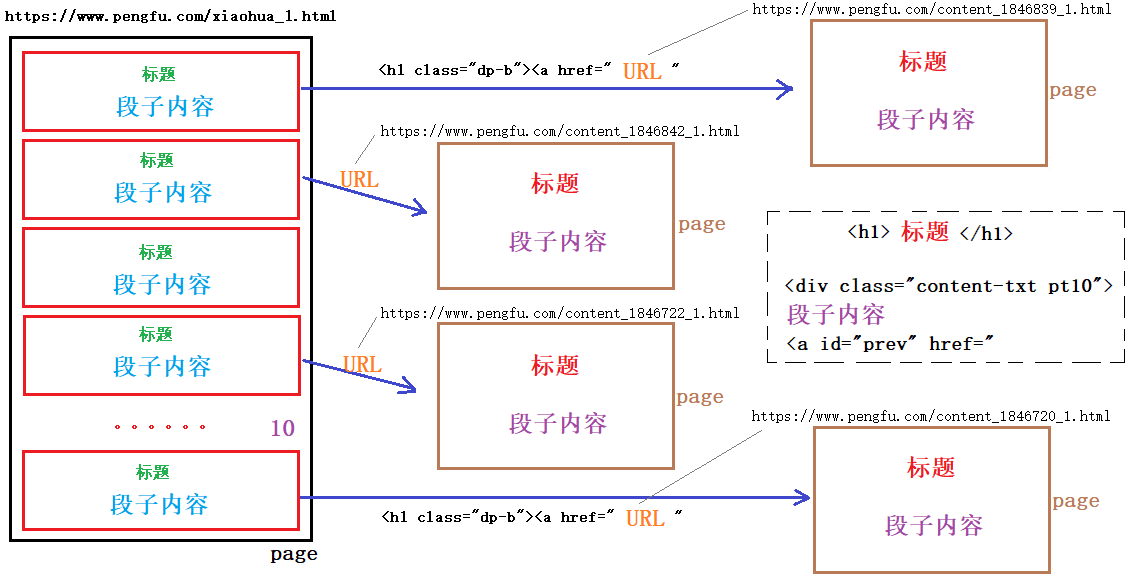
使用浏览器自带功能,查看网页源码,每一个网页中共有 10 条段子。每个标题都对应有一个独立的URL链接,该URL以 <h1 class="dp-b"><a href=开头,以"结尾。搜索发现,共有10处。
点击该链接,可以打开一个独立的页面,包含该段子对应的标题及内容。也就是说,主页中的10条段子,可以在10个网页中分别呈现。
查看一个段子网页源码,找寻“标题”和“正文内容”规律。发现:标题被包裹在 <h1> 标题 </h1> 中。而正文内容被包裹在 <div class="content-txt pt10"> 正文内容 <a id="prev" href="中。
整体页面组织结构如下图所示:
根据上述分析,爬取“捧腹网”段子内容,大致可以分为三步实现。 第一,先获取网页规律,根据用户指定起始、终止页打开要爬取的网页。并获取每一个网页中单个段子所对应页面的URL。 第二,依次将每一个段子对应的网页打开,读取标题和正文内容。 第三,将一个网页内容(10个段子)保存成一个 .txt文件。
爬取段子
按照上述分析,依次编码代码实现。首先提取一个网页中10个段子所对应页面的URL。
1package main
2
3import (
4 "fmt"
5 "net/http"
6 "regexp"
7 "strconv"
8)
9
10func httpGet(url string) (result string, err error) {
11 resp, err1 := http.Get(url)
12 if err1 != nil {
13 err = err1
14 return
15 }
16 defer resp.Body.Close()
17 buf := make([]byte, 4096)
18 for {
19 n, _ := resp.Body.Read(buf)
20 if n == 0 {
21 break
22 }
23 result += string(buf[:n])
24 }
25 return
26}
27
28func spiderPage(idx int) {
29 // https://www.pengfu.com/xiaohua_6.html
30 url := "https://www.pengfu.com/xiaohua_" + strconv.Itoa(idx) + ".html"
31 result, err := httpGet(url)
32 if err != nil {
33 fmt.Println("httpGet err:", err)
34 return
35 }
36 // fmt.Println(result)
37 // 从 result 中提取各个段子的url, <h1 class="dp-b"><a href=" 一个段子的URL " 使用正则表达式:
38 // 解析编译正则表达式
39 ret := regexp.MustCompile(`<h1 class="dp-b"><a href="(?s:(.*?))"`)
40 if ret == nil {
41 fmt.Println("regexp.MustCompile err:", err)
42 return
43 }
44 // 2.取需要信息
45 alls := ret.FindAllStringSubmatch(result, -1)
46
47 // 提取一个段子的 URL
48 for _, jokeURL := range alls {
49 fmt.Println("url=", jokeURL[1])
50 }
51}
52
53func working(start, end int) {
54 // 测试
55 fmt.Printf("正在爬取 %d 到 %d 页\n", start, end)
56
57 for i := start; i <= end; i++ {
58 spiderPage(i)
59 }
60}
61
62func main() {
63 // 指定爬取的起始、终止页面
64 var start, end int
65 fmt.Printf("请输入爬取的起始页( >= 1 ):")
66 fmt.Scan(&start)
67 fmt.Printf("请输入爬取的终止页( >= 起始页):")
68 fmt.Scan(&end)
69
70 // 封装函数,专门完成爬取工作。
71 working(start, end)
72}
接下来完成第二步, 封装函数将每一个段子所对应的页面中的标题和正文内容取出。
1func spiderJokePage(jokeURL string) (title, content string, err error) {
2 // 读取段子页面内容
3 result, err := httpGet(jokeURL)
4 if err != nil {
5 return
6 }
7 //解析、编译正则表达式, 处理 title —— <h1> 段子标题 </h1>
8 ret1 := regexp.MustCompile(`<h1>(?s:(.*?))</h1>`)
9 if ret1 == nil {
10 err = fmt.Errorf("%s", "MustCompile err")
11 return
12 }
13 // 提取 title
14 // 有两处,取第一处
15 tmpTitle := ret1.FindAllStringSubmatch(result, 1)
16 for _, data := range tmpTitle {
17 // 存至返回值 title
18 title = data[1]
19 title = strings.Replace(title, "\t", "", -1)
20 // 取一个即可。
21 break
22 }
23
24 //解析、编译正则表达式, 处理 content —— <div class="content-txt pt10"> 段子内容 <a id="prev" href="
25 ret2 := regexp.MustCompile(`<div class="content-txt pt10">(?s:(.*?))<a id="prev" href="`)
26 if ret2 == nil {
27 err = fmt.Errorf("%s", "MustCompile err")
28 return
29 }
30 // 提取 Content
31 // 只有一处
32 tmpContent := ret2.FindAllStringSubmatch(result, -1)
33 for _, data := range tmpContent {
34 // 存至返回值 content
35 content = data[1]
36 content = strings.Replace(content, "\t", "", -1)
37 // 提取一个即可。
38 break
39 }
40 return
41}
第三步,封装函数,将每页的10个段子标题及内容保存成一个.txt文件,以页号命名此文件。由于反复打开追加实现较为复杂,首先我们先将读到的所有标题和正文内容保存到 []string 中,然后一次性写入文件。
1func saveJoke2File(idx int, fileTitle, fileContent []string) {
2 f, err := os.Create(strconv.Itoa(idx) + ".txt")
3 if err != nil {
4 fmt.Println("Create err:", err)
5 return
6 }
7 defer f.Close()
8
9 n := len(fileTitle)
10 for i:=0; i<n; i++ {
11 // 写入标题
12 f.WriteString(fileTitle[i] + "\n")
13 // 写入内容
14 f.WriteString(fileContent[i] + "\n")
15 // 写一个华丽分割线
16 f.WriteString("--------------------------------------------------------------\n")
17 }
18}
测试,可以完成从指定网页中提取段子标题和正文,存至文件中。但由于需要写出成文件,操作IO,较少网页的保存尚可,当需要保存的网页过多时,运行速度很慢。 与百度贴吧的处理思路相同。我们可以借助 goroutine 和 channel 完成并发,提高爬取速度。
并发实现
很简单,只需要起一个 goroutine 去调用spiderPage函数即可。但同样需要借助channel,控制主goroutine在创建子协程完成后,不会立即结束。
1func working(start, end int) {
2 fmt.Printf("正在爬取 %d 到 %d 页\n", start, end) // 测试
3
4 page := make(chan int)
5
6 for i:=start; i<=end; i++ {
7 go spiderPage(i, page)
8 }
9
10 for i:=start; i<=end; i++ {
11 fmt.Printf("第%d个页面爬取完毕\n", <-page)
12 }
13}
同时当然也需要在 spiderPage 函数结尾处,向page通道中写入数据。完成同步。
爬取IMDB电影
本来想爬豆瓣的,做了反爬虫机制,换IMDB的了。
IMDB电影排行地址:http://www.imdb.cn/IMDB250/
爬取的思路与上面案例的思路是一样的,注意的地方就是在正则表达式。
完整代码如下:
1package main
2
3import (
4 "fmt"
5 "net/http"
6 "os"
7 "regexp"
8 "strconv"
9 "time"
10)
11
12//发起请求,获取网页内容
13func httpGet(url string) (result string, err error) {
14 //发送get请求
15 resp, err := http.Get(url)
16 if err != nil {
17 return
18 }
19
20 defer resp.Body.Close()
21
22 //读取网页内容
23 buf := make([]byte, 4*1024)
24 for {
25 n, _ := resp.Body.Read(buf)
26 if n == 0 {
27 break
28 }
29 //累加读取的内容
30 result += string(buf[:n])
31 }
32 return
33}
34
35func spiderPape(i int, page chan int) {
36 //明确爬取的url
37 fmt.Println("正在抓取第" + strconv.Itoa(i) + "页......")
38 url := "http://www.imdb.cn/imdb250/" + strconv.Itoa(i)
39
40 time.Sleep(1 * time.Second)
41 //开始爬取页面内容
42 result, err := httpGet(url)
43
44 if err != nil {
45 fmt.Println("httpGet err = ", err)
46 return
47 }
48
49 //电影名称
50 // <p class="bb">肖申克的救赎</p>
51 pattern4 := `<p class="bb">(.*?)</p>`
52 rp4 := regexp.MustCompile(pattern4)
53 fName := rp4.FindAllStringSubmatch(result, -1)
54
55 //评分
56 // <span><i>9.3</i></span>
57 pattern3 := `<span><i>(.*?)</i></span>`
58 rp3 := regexp.MustCompile(pattern3)
59 fScore := rp3.FindAllStringSubmatch(result, -1)
60
61 // 年代
62 // 年代:<i>1994年</i>
63 re := regexp.MustCompile(`年代:<i>(.*?)年</i>`)
64 age := re.FindAllStringSubmatch(result, -1)
65
66 //把内容写入到文件
67 storeJoyToFile(i, age, fScore, fName)
68
69 //写内容,写num
70 page <- i
71}
72
73//把内容写入到文件
74func storeJoyToFile(i int, age, fScore, fName [][]string) {
75 //新建文件
76 f, err := os.Create(strconv.Itoa(i) + ".txt")
77 if err != nil {
78 fmt.Println("os.Create err = ", err)
79 return
80 }
81
82 defer f.Close()
83 //写入标题
84 f.WriteString("电影名称" + "\t" + "评分" + "\t" + "年代" + "\t" + "\r\n")
85
86 //写内容
87 n := len(age)
88 fmt.Println("n=", n)
89 for i := 0; i < n; i++ {
90 f.WriteString(fName[i][1] + "\t" + fScore[i][1] + "\t" + age[i][1] + "\t" + "\r\n")
91 }
92
93}
94
95func doWork(start, end int) {
96 fmt.Printf("准备爬取第%d页到%d页的网址\n", start, end)
97 page := make(chan int)
98 for i := start; i <= end; i++ {
99 //定义一个函数,爬主页面
100 go spiderPape(i, page)
101 }
102
103 for i := start; i <= end; i++ {
104 fmt.Printf("第%d个页面爬取完成\n", <-page)
105 }
106
107}
108
109func main() {
110 var start, end int
111 fmt.Printf("请输入起始页( >= 1 ) :")
112 fmt.Scan(&start)
113 fmt.Printf("请输入终止页( >= 起始页 ) :")
114 fmt.Scan(&end)
115
116 doWork(start, end) //工作函数
117}
运行效果
1请输入起始页( >= 1) :1
2请输入终止页( >= 起始页) :9
3准备爬取第1页到9页的网址
4正在抓取第1页......
5正在抓取第9页......
6正在抓取第7页......
7正在抓取第6页......
8正在抓取第8页......
9正在抓取第3页......
10正在抓取第5页......
11正在抓取第2页......
12正在抓取第4页......
13n= 7
14第9个页面爬取完成
15n= 30
16第5个页面爬取完成
17n= 30
18第7个页面爬取完成
19n= 30
20第8个页面爬取完成
21n= 30
22第6个页面爬取完成
23n= 30
24第4个页面爬取完成
25n= 30
26第3个页面爬取完成
27n= 30
28第1个页面爬取完成
29n= 30
30第2个页面爬取完成
查看文件
1ls *.txt
21.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt
3
4cat 1.txt
5电影名称 评分 年代
6肖申克的救赎 9.3 1994
7教父 9.2 1972
8教父:II 9.1 1974
9低俗小说 9.0 1994
10黄金三镖客 9.0 1966
11蝙蝠侠前传2:黑暗骑士 9.0 0
12十二怒汉 8.9 1957
13辛德勒名单 8.9 1993
14指环王:王者归来 8.9 2003
15搏击俱乐部 8.9 1999
16星球大战Ⅴ:帝国反击战 8.8 1980
17指环王:护戒使者 8.8 2001
18飞越疯人院 8.8 1975
19盗梦空间 8.8 2010
20好家伙 8.8 1990
21星球大战IV:新希望 8.8 1977
22七武士 8.8 1954
23阿甘正传 8.7 1994
24黑客帝国 8.7 1999
25指环王:双塔奇兵 8.7 2002
26上帝之城 8.7 2002
27七宗罪 8.7 1995
28沉默的羔羊 8.7 1991
29西部往事 8.7 1968
30卡萨布兰卡 8.7 1942
31非常嫌疑犯 8.7 1995
32夺宝奇兵 8.7 1981
33后窗 8.7 1954
34美好人生 8.7 1946
35惊魂记 8.6 1960
更高级应用:爬取有价值的信息,并对这些信息进行更近一步的整合,实现大数据的实战应用。
- 原文作者:黄忠德
- 原文链接:https://huangzhongde.cn/post/Golang/go_spider/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。